This page was generated from examples/models/openvino_imagenet_ensemble/openvino_imagenet_ensemble.ipynb.
Pipeline example with OpenVINO inference execution engine¶
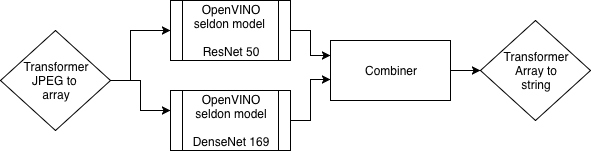
This notebook illustrates how you can serve ensemble of models using OpenVINO prediction model. The demo includes optimized ResNet50 and DenseNet169 models by OpenVINO model optimizer. They have reduced precision of graph operations from FP32 to INT8. It significantly improves the execution peformance with minimal impact on the accuracy. The gain is particularly visible with the latest Casade Lake CPU with VNNI extension.
Setup Seldon Core¶
Use the setup notebook to Setup Cluster with Ambassador Ingress and Install Seldon Core. Instructions also online.
[ ]:
!kubectl create namespace seldon
[ ]:
!kubectl config set-context $(kubectl config current-context) --namespace=seldon
Deploy Seldon pipeline with Intel OpenVINO models ensemble¶
Ingest compressed JPEG binary and transform to TensorFlow Proto payload
Ensemble two OpenVINO optimized models for ImageNet classification: ResNet50, DenseNet169
Return result in human readable text
[ ]:
!pygmentize seldon_ov_predict_ensemble.yaml
[ ]:
!kubectl apply -f seldon_ov_predict_ensemble.yaml
[ ]:
!kubectl rollout status deploy/$(kubectl get deploy -l seldon-deployment-id=openvino-model -o jsonpath='{.items[0].metadata.name}')
Using the exemplary grpc client¶
Install client dependencies: seldon-core and grpcio packages
[ ]:
!pip install -q seldon-core grpcio
[ ]:
!python seldon_grpc_client.py --debug --ambassador localhost:8003
For more extensive test see the client help.
You can change the default test-input file including labeled list of images to calculate accuracy based on complete imagenet dataset. Follow the format from file input_images.txt - path to the image and imagenet class in every line.
[ ]:
!python seldon_grpc_client.py --help
Examining the logs¶
You can use Seldon containers logs to get additional details about the execution:
[ ]:
!kubectl logs $(kubectl get pods -l seldon-app=openvino-model-openvino -o jsonpath='{.items[0].metadata.name}') prediction1 --tail=10
[ ]:
!kubectl logs $(kubectl get pods -l seldon-app=openvino-model-openvino -o jsonpath='{.items[0].metadata.name}') prediction2 --tail=10
[ ]:
!kubectl logs $(kubectl get pods -l seldon-app=openvino-model-openvino -o jsonpath='{.items[0].metadata.name}') imagenet-itransformer --tail=10
Performance consideration¶
In production environment with a shared workloads, you might consider contraining the CPU resources for individual pipeline components. You might restrict the assigned capacity using Kubernetes capabilities. This configuration can be added to seldon pipeline definition.
Another option for tuning the resource allocation is adding environment variable OMP_NUM_THREADS. It can indicate how many threads will be used by OpenVINO execution engine and how many CPU cores can be consumed. The recommended value is equal to the number of allocated CPU physical cores.
In the tests using GKE service in Google Cloud on nodes with 32 SkyLake vCPU assigned, the following configuration was set on prediction components. It achieved the optimal latency and throughput:
"resources": {
"requests": {
"cpu": "1"
},
"limits": {
"cpu": "32"
}
}
"env": [
{
"name": "KMP_AFFINITY",
"value": "granularity=fine,verbose,compact,1,0"
},
{
"name": "KMP_BLOCKTIME",
"value": "1"
},
{
"name": "OMP_NUM_THREADS",
"value": "8"
}
]
[ ]:
!kubectl delete -f seldon_ov_predict_ensemble.json