This page was generated from examples/triton_gpt2/GPT2-ONNX-Azure.ipynb.
Pretrained GPT2 Model Deployment Example¶
In this notebook, we will run an example of text generation using GPT2 model exported from HuggingFace and deployed with Seldon’s Triton pre-packed server. the example also covers converting the model to ONNX format. The implemented example below is of the Greedy approach for the next token prediction. more info: https://huggingface.co/transformers/model_doc/gpt2.html?highlight=gpt2
After we have the module deployed to Kubernetes, we will run a simple load test to evaluate the module inference performance.
Steps:¶
Create PersistentVolume and PVC mounting Azure Storage Blob
Setup Seldon-Core in your kubernetes cluster
Deploy the ONNX model with Seldon’s prepackaged Triton server.
Run model inference, run a greedy alg example (generate sentence completion)
Basic requirements¶
Helm v3.0.0+
A Kubernetes cluster running v1.13 or above (minkube / docker-for-windows work well if enough RAM)
kubectl v1.14+
Python 3.6+
[ ]:
%%writefile requirements.txt
transformers==4.5.1
torch==1.8.1
tokenizers<0.11,>=0.10.1
tensorflow==2.4.1
tf2onnx
[ ]:
!pip install --trusted-host=pypi.python.org --trusted-host=pypi.org --trusted-host=files.pythonhosted.org -r requirements.txt
Export HuggingFace TFGPT2LMHeadModel pre-trained model and save it locally¶
[ ]:
from transformers import GPT2Tokenizer, TFGPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = TFGPT2LMHeadModel.from_pretrained(
"gpt2", from_pt=True, pad_token_id=tokenizer.eos_token_id
)
model.save_pretrained("./tfgpt2model", saved_model=True)
Convert the TensorFlow saved model to ONNX¶
[ ]:
!python -m tf2onnx.convert --saved-model ./tfgpt2model/saved_model/1 --opset 13 --output model.onnx
Azure Setup¶
We have provided Azure Setup Notebook that deploys AKS cluster, Azure storage account and installs Azure Blob CSI driver. If AKS cluster already exists skip to creation of Blob Storage and CSI driver installtion steps. Upon completion of Azure setup following infrastructure will be created: 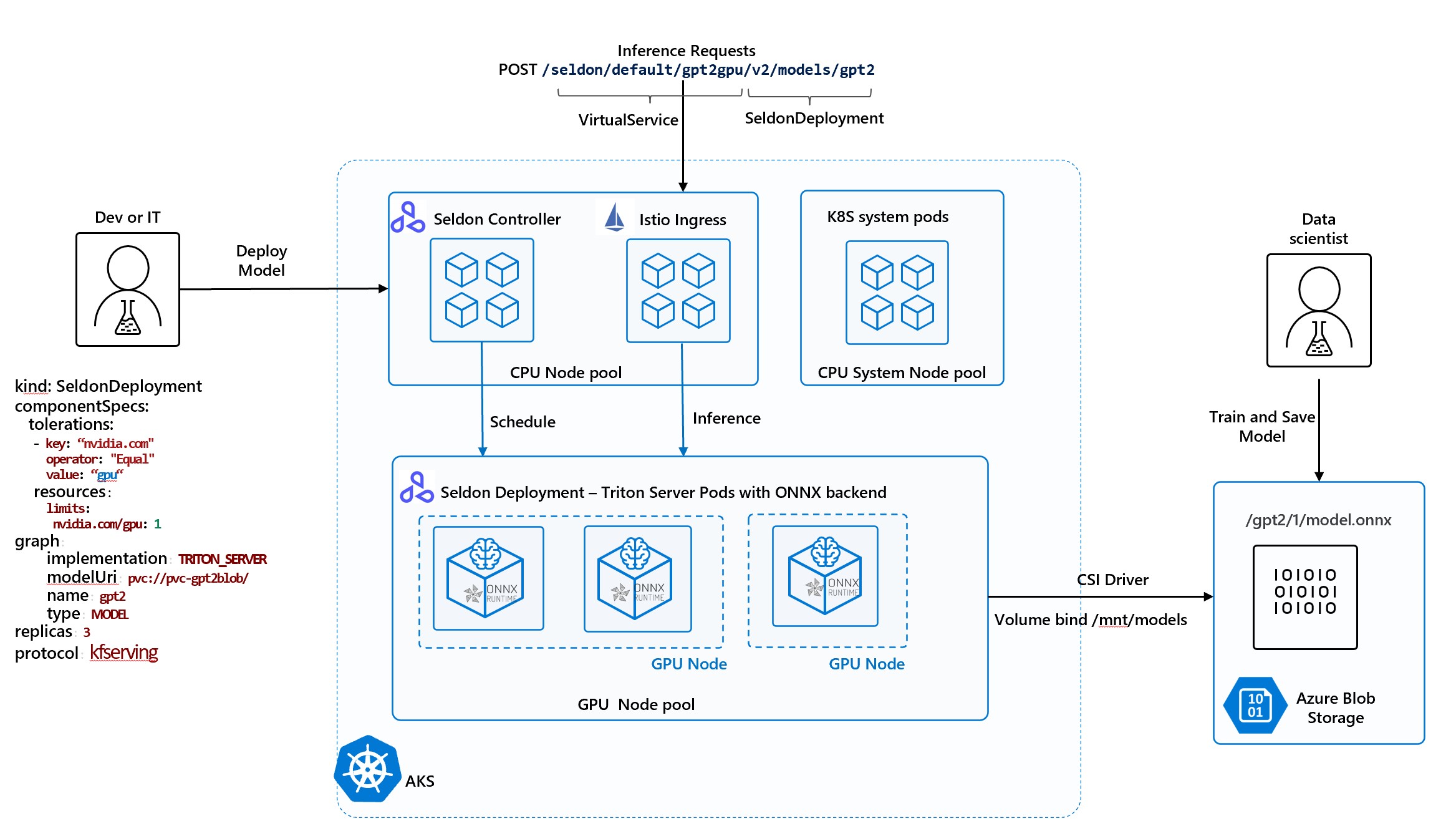
[1]:
resource_group = "seldon" # feel free to replace or use this default
aks_name = "modeltests"
storage_account_name = "modeltestsgpt" # fill in
storage_container_name = "gpt2onnx"
Copy your model to Azure Blob¶
[ ]:
%%time
# Copy model file
!az extension add --name storage-preview
!az storage azcopy blob upload --container {storage_container_name} \
--account-name {storage_account_name} \
--source ./model.onnx \
--destination gpt2/1/model.onnx
[3]:
#Verify Uploaded file
!az storage blob list \
--account-name {storage_account_name}\
--container-name {storage_container_name} \
--output table
This command has been deprecated and will be removed in future release. Use 'az storage fs file list' instead. For more information go to https://github.com/Azure/azure-cli/blob/dev/src/azure-cli/azure/cli/command_modules/storage/docs/ADLS%20Gen2.md
The behavior of this command has been altered by the following extension: storage-preview
Name IsDirectory Blob Type Blob Tier Length Content Type Last Modified Snapshot
----------------- ------------- ----------- ----------- --------- ------------------------ ------------------------- ----------
gpt2/1/model.onnx BlockBlob Hot 652535462 application/octet-stream 2021-05-28T04:37:11+00:00
Add Azure PersistentVolume and Claim¶
For more details on creating PersistentVolume using CSI driver refer to https://github.com/kubernetes-sigs/blob-csi-driver/blob/master/deploy/example/e2e_usage.md - Create secret - Create PersistentVolume pointing to secret and Blob Container Name and mountOptions specifying user id for non-root containers - Creare PersistentVolumeClaim to bind to volume
[ ]:
key = !az storage account keys list --account-name {storage_account_name} -g {resource_group} --query '[0].value' -o tsv
storage_account_key = key[0]
[ ]:
# Create secret to access storage account
!kubectl create secret generic azure-blobsecret --from-literal azurestorageaccountname={storage_account_name} --from-literal azurestorageaccountkey="{storage_account_key}" --type=Opaque
[ ]:
%%writefile azure-blobfuse-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-gpt2blob
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain # "Delete" is not supported in static provisioning
csi:
driver: blob.csi.azure.com
readOnly: false
volumeHandle: trainingdata # make sure this volumeid is unique in the cluster
volumeAttributes:
containerName: gpt2onnx # Modify if changed in Notebook
nodeStageSecretRef:
name: azure-blobsecret
namespace: default
mountOptions: # Use same user id that is used by POD security context
- -o uid=8888
- -o allow_other
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pvc-gpt2blob
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
volumeName: pv-gpt2blob
storageClassName: ""
[2]:
!kubectl apply -f azure-blobfuse-pv.yaml
persistentvolume/pv-gptblob configured
persistentvolumeclaim/pvc-gptblob unchanged
[4]:
# Verify PVC is bound
!kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pv-gpt2blob 10Gi RWX Retain Bound default/pvc-gpt2blob 4h54m
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/pvc-gpt2blob Bound pv-gpt2blob 10Gi RWX 4h54m
Run Seldon in your kubernetes cluster¶
Follow the Seldon-Core Setup notebook to Setup a cluster with Istio Ingress and install Seldon Core
Deploy your model with Seldon pre-packaged Triton server¶
[7]:
%%writefile gpt2-deploy.yaml
apiVersion: machinelearning.seldon.io/v1alpha2
kind: SeldonDeployment
metadata:
name: gpt2gpu
spec:
annotations:
prometheus.io/port: "8002" # we will explain below in Monitoring section
prometheus.io/path: "/metrics"
predictors:
- componentSpecs:
- spec:
containers:
- name: gpt2
resources:
requests:
memory: 2Gi
cpu: 2
nvidia.com/gpu: 1
limits:
memory: 4Gi
cpu: 4
nvidia.com/gpu: 1
tolerations:
- key: "nvidia.com" # to be able to run in GPU Nodepool
operator: "Equal"
value: "gpu"
effect: "NoSchedule"
graph:
implementation: TRITON_SERVER
logger:
mode: all
modelUri: pvc://pvc-gpt2blob/
name: gpt2
type: MODEL
name: default
replicas: 1
protocol: kfserving
Overwriting gpt2-deploy.yaml
[6]:
!kubectl apply -f gpt2-deploy.yaml -n default
seldondeployment.machinelearning.seldon.io/gpt2 created
[3]:
!kubectl rollout status deploy/$(kubectl get deploy -l seldon-deployment-id=gpt2gpu -o jsonpath='{.items[0].metadata.name}')
deployment "gpt2gpu-default-0-gpt2" successfully rolled out
Interact with the model: get model metadata (a “test” request to make sure our model is available and loaded correctly)¶
[1]:
ingress_ip = !(kubectl get svc --namespace istio-system istio-ingressgateway -o jsonpath='{.status.loadBalancer.ingress[0].ip}')
ingress_ip = ingress_ip[0]
!curl -v http://{ingress_ip}:80/seldon/default/gpt2gpu/v2/models/gpt2
* Trying 20.75.117.145:80...
* TCP_NODELAY set
* Connected to 20.75.117.145 (20.75.117.145) port 80 (#0)
* Mark bundle as not supporting multiuse
* Connection #0 to host 20.75.117.145 left intact
{"name":"gpt2","versions":["1"],"platform":"onnxruntime_onnx","inputs":[{"name":"input_ids:0","datatype":"INT32","shape":[-1,-1]},{"name":"attention_mask:0","datatype":"INT32","shape":[-1,-1]}],"outputs":[{"name":"past_key_values","datatype":"FP32","shape":[12,2,-1,12,-1,64]},{"name":"logits","datatype":"FP32","shape":[-1,-1,50257]}]}
Run prediction test: generate a sentence completion using GPT2 model - Greedy approach¶
[11]:
import http
import json
import numpy as np
import requests
from transformers import GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
input_text = "I love Artificial Intelligence"
count = 0
max_gen_len = 8
gen_sentence = input_text
while count < max_gen_len:
input_ids = tokenizer.encode(gen_sentence, return_tensors="tf")
shape = input_ids.shape.as_list()
payload = {
"inputs": [
{
"name": "input_ids:0",
"datatype": "INT32",
"shape": shape,
"data": input_ids.numpy().tolist(),
},
{
"name": "attention_mask:0",
"datatype": "INT32",
"shape": shape,
"data": np.ones(shape, dtype=np.int32).tolist(),
},
]
}
tfserving_url = (
"http://" + str(ingress_ip) + "/seldon/default/gpt2gpu/v2/models/gpt2/infer"
)
print(f"sending request to {tfserving_url}")
with requests.post(tfserving_url, json=payload) as ret:
try:
res = ret.json()
except:
continue
# extract logits
logits = np.array(res["outputs"][1]["data"])
logits = logits.reshape(res["outputs"][1]["shape"])
# take the best next token probability of the last token of input ( greedy approach)
next_token = logits.argmax(axis=2)[0]
next_token_str = tokenizer.decode(
next_token[-1:], skip_special_tokens=True, clean_up_tokenization_spaces=True
).strip()
gen_sentence += " " + next_token_str
print(f"Sentence: {gen_sentence}")
count += 1
print(f"Input: {input_text}\nOutput: {gen_sentence}")
sending request to http://20.75.117.145/seldon/default/gpt2gpu/v2/models/gpt2/infer
Sentence: I love Artificial Intelligence .
sending request to http://20.75.117.145/seldon/default/gpt2gpu/v2/models/gpt2/infer
Sentence: I love Artificial Intelligence . I
sending request to http://20.75.117.145/seldon/default/gpt2gpu/v2/models/gpt2/infer
Sentence: I love Artificial Intelligence . I love
sending request to http://20.75.117.145/seldon/default/gpt2gpu/v2/models/gpt2/infer
Sentence: I love Artificial Intelligence . I love the
sending request to http://20.75.117.145/seldon/default/gpt2gpu/v2/models/gpt2/infer
Sentence: I love Artificial Intelligence . I love the way
sending request to http://20.75.117.145/seldon/default/gpt2gpu/v2/models/gpt2/infer
Sentence: I love Artificial Intelligence . I love the way it
sending request to http://20.75.117.145/seldon/default/gpt2gpu/v2/models/gpt2/infer
Sentence: I love Artificial Intelligence . I love the way it 's
sending request to http://20.75.117.145/seldon/default/gpt2gpu/v2/models/gpt2/infer
Sentence: I love Artificial Intelligence . I love the way it 's designed
Input: I love Artificial Intelligence
Output: I love Artificial Intelligence . I love the way it 's designed
Configure Model Monitoring with Azure Monitor¶
The Azure Monitor Containers Insights provides functionality to allow collecting data from any Prometheus endpoints. It removes the need to install and operate Prometheus server and manage the monitoring data as Azure Monitor provides centralized point for collecting, displaying and alerting on monitoring data. To turn on Azure Monitor Container Insights follow steps described here and you should that you have an “omsagent” pod running.
[5]:
!kubectl get pods -n kube-system | grep omsagent
omsagent-27lk7 1/1 Running 3 12d
omsagent-7q49d 1/1 Running 3 12d
omsagent-9slf6 1/1 Running 3 12d
omsagent-kzbkr 1/1 Running 3 12d
omsagent-q85hk 1/1 Running 3 12d
omsagent-rs-5976fbdc8b-rgxs4 1/1 Running 0 8d
omsagent-tpkq2 1/1 Running 3 12d
Configure Prometheus Metrics scraping¶
Once omsagent is running we need to configure it to collect metrics from Prometheus endpoints. Azure Monitor Containers Insights allows configuration to be applied on a cluster or node-wide scope and configure endpoints for monitoring on one of the following ways: - Provide an array of URLs - Provide an Array of Kubernetes services - Enable monitoring of any pods with Prometheus annotations For more details on how to configure the scraping endpoints and query collected data refer to MS Docs
on Configure scraping of Prometheus metrics with Container insights
Our deployed model metrics are availble from couple infrasture layers - Seldon model orchestrator metrics and Nvidia Triton Server Metrics. To enable scraping for both endpoints we updated Microsoft provided default ConfigMap that configures omsagent azure-metrics-cm.yaml: - Triton
Server: update monitor_kubernetes_pods = true to enable scrapting for Pods with prometheus.io annotations In SeldonDeployment shown above prometheus.io/path and prometheus.io/port point to default Triton metrics endpoint - Seldon Orchestrator: add our deployed model seldon service endpoint to list of Kubernetes services to be scraped: yaml kubernetes_services = ["http://gpt2gpu-default.default:8000/prometheus"]
[ ]:
!kubectl apply -f azure-metrics-cm.yaml
Query and Visualize collected data¶
Collected metrics are available in Logs blade of Azure Monitor in a table InsightsMetrics, you could see all metrics gathered by running query
InsightsMetrics
| where Namespace == "prometheus"
To get Model Inference Requests per minute from Seldon Metrics run the following query and pin it to Dashboard or add to Azure Monitor Workbook:
InsightsMetrics
| where Namespace == "prometheus"
| where Name == "seldon_api_executor_server_requests_seconds_count"
| extend Model = parse_json(Tags).deployment_name
| where parse_json(Tags).service == "predictions"
| order by TimeGenerated asc
| extend RequestsPerMin = Val - prev(Val,1)
| project TimeGenerated, RequestsPerMin
| render areachart
To get Inference Duration from Triton Metrics:
InsightsMetrics
| where Namespace == "prometheus"
| where Name in ("nv_inference_request_duration_us")
| order by TimeGenerated asc
| extend QueueDurationSec = (Val - prev(Val, 1)) / 1000
| project TimeGenerated, Name, QueueDurationSec
| render areachart
Here is example dashboard we created using queries above
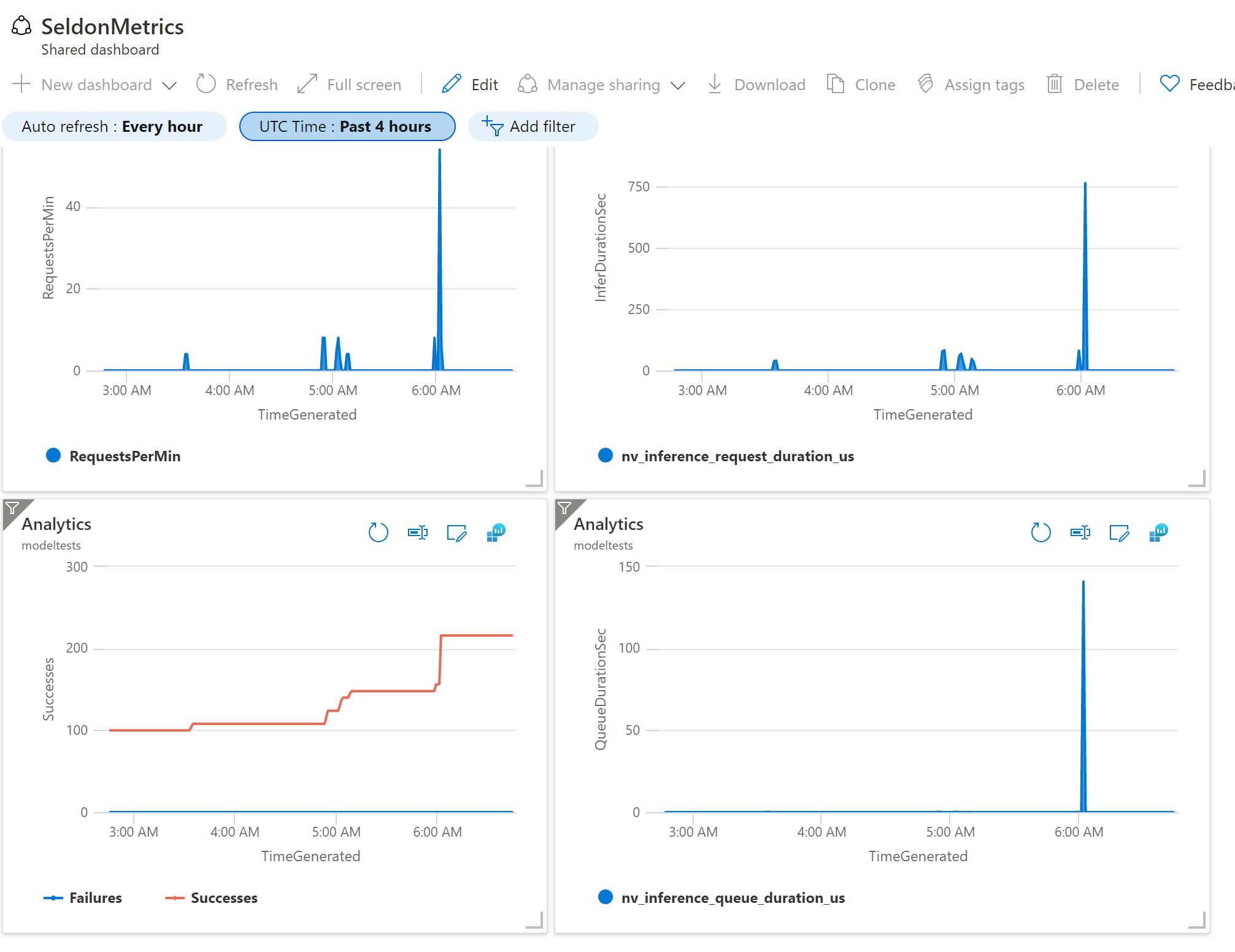
Run Load Test / Performance Test using vegeta¶
Install vegeta, for more details take a look in vegeta official documentation¶
[20]:
!wget https://github.com/tsenart/vegeta/releases/download/v12.8.3/vegeta-12.8.3-linux-arm64.tar.gz
!tar -zxvf vegeta-12.8.3-linux-arm64.tar.gz
!chmod +x vegeta
--2021-05-28 18:40:27-- https://github.com/tsenart/vegeta/releases/download/v12.8.3/vegeta-12.8.3-linux-arm64.tar.gz
Resolving github.com (github.com)... 140.82.114.4
Connecting to github.com (github.com)|140.82.114.4|:443... connected.
HTTP request sent, awaiting response... 302 Found
Location: https://github-releases.githubusercontent.com/12080551/ba68d580-6e90-11ea-8bd2-3f43f5c08b3c?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20210528%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20210528T224014Z&X-Amz-Expires=300&X-Amz-Signature=2efad77c33f1663eea17d366986bfad1cd081128d45012c9b6e6659c4c80eff6&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=12080551&response-content-disposition=attachment%3B%20filename%3Dvegeta-12.8.3-linux-arm64.tar.gz&response-content-type=application%2Foctet-stream [following]
--2021-05-28 18:40:27-- https://github-releases.githubusercontent.com/12080551/ba68d580-6e90-11ea-8bd2-3f43f5c08b3c?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20210528%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20210528T224014Z&X-Amz-Expires=300&X-Amz-Signature=2efad77c33f1663eea17d366986bfad1cd081128d45012c9b6e6659c4c80eff6&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=12080551&response-content-disposition=attachment%3B%20filename%3Dvegeta-12.8.3-linux-arm64.tar.gz&response-content-type=application%2Foctet-stream
Resolving github-releases.githubusercontent.com (github-releases.githubusercontent.com)... 185.199.108.154, 185.199.109.154, 185.199.110.154, ...
Connecting to github-releases.githubusercontent.com (github-releases.githubusercontent.com)|185.199.108.154|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 3281900 (3.1M) [application/octet-stream]
Saving to: ‘vegeta-12.8.3-linux-arm64.tar.gz.2’
vegeta-12.8.3-linux 100%[===================>] 3.13M 2.95MB/s in 1.1s
2021-05-28 18:40:28 (2.95 MB/s) - ‘vegeta-12.8.3-linux-arm64.tar.gz.2’ saved [3281900/3281900]
CHANGELOG
LICENSE
README.md
vegeta
Generate vegeta target file contains “post” cmd with payload in the requiered structure¶
[3]:
import base64
import json
from subprocess import PIPE, Popen, run
import numpy as np
from transformers import GPT2Tokenizer, TFGPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
input_text = "I enjoy working in Seldon"
input_ids = tokenizer.encode(input_text, return_tensors="tf")
shape = input_ids.shape.as_list()
payload = {
"inputs": [
{
"name": "input_ids:0",
"datatype": "INT32",
"shape": shape,
"data": input_ids.numpy().tolist(),
},
{
"name": "attention_mask:0",
"datatype": "INT32",
"shape": shape,
"data": np.ones(shape, dtype=np.int32).tolist(),
},
]
}
tfserving_url = (
"http://" + str(ingress_ip) + "/seldon/default/gpt2gpu/v2/models/gpt2/infer"
)
print(f"preparing request to {tfserving_url}")
cmd = {
"method": "POST",
"header": {"Content-Type": ["application/json"]},
"url": tfserving_url,
"body": base64.b64encode(bytes(json.dumps(payload), "utf-8")).decode("utf-8"),
}
with open("vegeta_target.json", mode="w") as file:
json.dump(cmd, file)
file.write("\n\n")
preparing request to http://20.75.117.145/seldon/default/gpt2gpu/v2/models/gpt2/infer
[5]:
!./vegeta attack -targets=vegeta_target.json -rate=1 -duration=60s -format=json | ./vegeta report -type=text
Requests [total, rate, throughput] 60, 1.02, 0.95
Duration [total, attack, wait] 1m3s, 58.994s, 4.445s
Latencies [min, mean, 50, 90, 95, 99, max] 1.45s, 4.003s, 3.983s, 5.249s, 6.329s, 7.876s, 7.97s
Bytes In [total, mean] 475803960, 7930066.00
Bytes Out [total, mean] 13140, 219.00
Success [ratio] 100.00%
Status Codes [code:count] 200:60
Error Set:
Clean-up¶
[ ]:
!kubectl delete -f gpt2-deploy.yaml -n default